什麼是Robots.txt
Robots.txt 是一個用於管理搜尋引擎爬蟲的文字檔案。
使用Robots来指示搜索引擎爬虫哪些页面或部分内容可以被抓取和索引,哪些不可以爬取。Robots规则档案通常位于网站的根目录下,名称为 robots.txt。
为什么Robots.txt对谷歌SEO很重要?
1.控制搜索引擎爬虫访问
网站管理员控制哪些页面或部分内容可以被搜索引擎爬虫访问和索引。这有助于避免不必要的页面被索引,例如:
重复内容
临时页面或测试页面
后台管理页面
无关紧要或低质量的页面
透过限制这些内容,可以提高重要页面在搜寻结果中的表现。
2.提高抓取效率
搜索引擎爬虫有一个抓取预算,即它们在每个网站上花费的时间和资源是有限的。透过使用 robots.txt 档案阻止爬虫访问无关或低价值的页面,可以将爬虫的抓取预算集中在更重要的页面上,从而提高这些页面的索引速度和频率。
3.遮蔽非公开页面
某些页面或档案可能包含敏感资讯(例如感谢页面),不希望被公开搜寻或索引。透过robots.txt,可以阻止搜索引擎爬虫访问这些内容,从而防止它们出现在搜寻结果中。
4.避免搜索引擎惩罚
一些搜索引擎(包括谷歌)可能会对重复内容、低质量页面或违反搜索引擎指南的内容进行惩罚。透过 robots.txt 档案,可以有效地管理和控制这些内容,避免不必要的搜索引擎惩罚,从而维护或提高网站的搜寻排名。
正确使用Robots.txt的流程
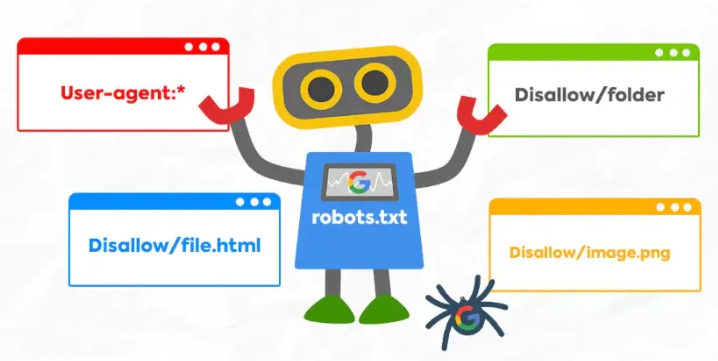
1.Robots规则
格式规范:
档案命名:档名必须为robots.txt,且全部字母小写。
存放位置:该档案应存放在网站的根目录下,即域名直接指向的目录。
格式:robots.txt档案应为纯文字档案,不包含任何HTML或指令码程式码。
注释:可以使用#符号新增注释,注释内容不会被搜索引擎解析。
空行:为了提高档案可读性,可以在指令之间留有空行。
指令与规则:
robots.txt档案由一系列的指令组成,每个指令占一行。常见的指令包括User-agent、Disallow、Allow和Sitemap。
①User-agent
作用:指定以下规则适用的搜索引擎爬虫名称
语法:User-agent: [爬虫名称]。其中,*代表适用于所有爬虫
示例:

Disallow
作用:指定禁止爬虫访问的URL路径
语法:Disallow: [路径]。路径可以使用万用字元*和$,其中*代表任意字元序列,$代表路径的结尾
示例:

Allow
作用:与Disallow相反,指定允许爬虫访问的URL路径。通常与Disallow一起使用,以覆盖更广泛的Disallow规则
语法:Allow: [路径],路径规则与Disallow相同。
示例:禁止爬虫访问整个 /wp-admin/ 目录,但需要允许访问 admin-ajax.php 档案。

Sitemap
作用:指定网站地图的URL地址,帮助搜索引擎更好地抓取网站内容
语法:Sitemap: [URL]
示例:

注意事项:
区分大小写:搜索引擎爬虫对大小写敏感,因此在编写robots.txt档案时需要注意区分大小写。
有效性验证:编写完毕可以透过搜索引擎工具或线上验证工具来验证robots.txt档案的有效性。
避免误封禁:在编写规则时要仔细检查,确保不会误封禁重要的网页或资源。
定期更新:根据网站的变化情况,定期更新robots.txt档案是必要的。
2.手动建立Robots档案
使用文字编辑器建立一个新的档案,并命名为 Robots.txt。在robots.txt 档案中新增你希望搜索引擎遵循的规则,编写示例:

该档案表示:
所有爬虫都不允许访问 /admin/, /login/ 和 /private/ 目录,但允许访问 /public/ 目录。
仅谷歌爬虫不允许访问 /test/ 目录。
最后新增上网站的Sitemap
3.Robots档案上传到网站